Implementing Filechute
I recently wrote about a vaporware Dropbox substitute called Filechute, starting with the abstract vision for it and promising that I'd get into the technical details of what an implementation might look like. That's what you're reading now. As I said in the other article, I'm not actually planning on building any of this right now, but it is fun to think and write about, so here we go.
Phase 1: Building on top of the existing filesystem
In order to minimize the time between conceiving of the design and having a usable prototype, in the first phase we'd build something that runs entirely in "application space", writing files to a store — really just an application-managed directory — in a traditional hierarchical filesystem, but presenting a UI that abstracts over it in such a way that the actual location of the files is an invisible implementation detail. The idea is that you can throw this data store into some folder that is already managed by Sync or Dropbox or Resilio Sync and let that program handle synchronization between machines. Because Filechute is going to store files in a directory that people aren't supposed to be poking around in, using cryptic names consisting of hexadecimal digits, it means that you would need to install and use the Filechute software on any machines where you wanted to interact with the store in any meaningful way; looking at the data using the Sync or Dropbox clients themselves won't be super meaningful.
Adding a file to the store
Following the tried-and-true content addressable storage model of programs such as Git, the actual location of a file within the store is derived from a hash of its contents. We can apply a hash function such as SHA-1 (currently used by Git, albeit with some well-known weaknesses), or a newer function such Skein, or SHA-256 (which Git is transitioning towards)1, to the file contents, producing a hash that we can render into convenient "human-readable" form as a string of hexadecimal digits. For the purposes of this discussion, we'll use 40-digit hexadecimal strings like those produced by SHA-1.
Say our input file, "December statement.pdf", produces a hash of a79065aca746c25342a83183d5e9a56262d1d826, and our store happens to be rooted at ~/Library/Application Support/dev.wincent.Filechute/2, we would store it in a location like $STORE/objects/a7/9065aca746c25342a83183d5e9a56262d1d826. We divide the hash space into 256 partitions by using the first two digits of the hash to decide which top-level directory — in the range of 00 to ff — to locate the file in, and then use the remaining digits as the name for the file containing the actual contents. This has the effect of distributing the data files across a large number of directories, and making it unlikely that any single directory will lead to scaling problems due to having an excessive number of files in it. As an example, if we store a couple hundred thousand files in the store, we would expect any given top-level directory to contain on the order of somewhat less than a thousand files3.
Another area where we take a leaf out of Git's book is in pretending that arcana such as resource forks and extended attributes simply don't exist. These have a checkered history, having adopted various different forms as Apple has evolved its operating system and released new filesystems. Each step of this journey has been plagued with compatibility and interoperability challenges. On Darwin, even venerable POSIX tools like cp and mv suffered the consequences; initially they did not preserve resource forks, requiring the use of a custom Apple tool called ditto instead, until they acquired the ability to deal with these special forks. This leads to internal complexity that they continue to carry around to this day. Git, on the other hand, chose very explicitly to focus on tracking content and that's it4, and thus neatly side-steps all of this hassle. This proves to be good enough for Git's purposes, and it will probably be just fine for Filechute as well.
Finding things
Shoving a file into the data store (writing a "blob" to the "object database" in Git parlance) is the easy bit. But what good is writing data in this inscrutable format if you can't easily find it again? Without some kind of index, we'll be in trouble if we want to find that "December statement.pdf" again, because we'll have to open every object in the store and check to see if it's the one we are looking for.
In Git, finding something like "the way src/index.js looked 10 commits ago" requires a traversal of some data structures that looks something like this:
- We read the
.git/HEADfile and see that it points us to therefs/heads/mainref. - We read
.git/refs/heads/main, and see that it points at a commit object with IDae35e630f(I'm abbreviating the full 40-character hexadecimal ID because the full string of digits isn't interesting here). - At this point we can start reading from the object database proper; the commit object tells us that its parent commit is an object with ID
92de4689f, and we can traverse from commit to commit following the parent chain in this way until we hit the desired 10th commit (in symbolic form,HEAD~10, but something likeddc054077as an ID). - That commit object points to a "tree" object
0a2d1f5b2, which represents the associated top-level directory; we can look up thesrcsubdirectory in that object and see that it is itself another tree object, with IDf074783fb. - Inside that tree object, we see that
index.jsis a "blob" with ID9ac0c07af. - Finally, we can read the object with that ID, and our work is done — we now know what
src/index.jslooked like atHEAD~10.
Now, Git's data structures are optimized for certain operations (eg. returning the state of the repository associated with a given commit) and are less optimized for others (eg. returning "blame" information for a long-lived but infrequently-modified file in a repository with a huge history). Filechute will have different operations that it cares about, so it will need different index data structures that are designed with those operations in mind. Project Nayuki's blog post, "Designing better file organization around tags, not hierarchies", which I already discussed in the previous article in this series, does a good job of explaining the types of operations that you might want to perform when working within a tag-based system, and some data structures that could be used to support those operations.
Let's assume that you can tag files with arbitrary tags. The key operations that follow are:
- Finding items with a specific tag.
- Finding items with a specific combination of tags; which we can break down further into two subcategories that correspond to different meanings of "combination":
- Logical "AND" (in set theory terms, intersection).
- Logical "OR" (in set theory terms, union).
In practical terms, the "AND" form is more powerful because it allows one to prune the search space in ways that make locating items even within an immense initial set easy to do. The "OR" form may prove useful on occasion too, particularly when you aren't exactly sure of the attributes that might be attached to the thing or things that you're looking for. But by default, the "AND" form is so useful that it suggests a UI paradigm in which one finds things by "drilling down" through the tag space, narrowing the result set by applying increasingly selective combinations of tags, until the desired item is found. The UI can guide the user in their search by not only providing a means of specifying additional tags, but also showing a UI that shows candidate tags at each level that can be used to narrow the search further.
I built a version of this kind of thing in a previous incarnation of this very website, back when it was a Rails app5. You would start at a so-called "tag cloud" that showed all the tags in use in the database, with font size being used to indicate which tags had the largest number of tagged items. Upon clicking on one of these tags, you would see a list of matching items in the main column, and a smaller version of the tag cloud would appear in the secondary column to guide your further search; in this tag cloud you would see tags that could be used to refine the search further (ie. showing items containing both tags), with size once again being used to indicate significance. The most heavily tagged items in the database tended to have anywhere between four and six tags, so "drilling down" to the item you were seeking was generally a matter of around that many clicks.
The code for this is visible here, in the tags_reachable_from_tags method. In this particular implementation, given that the tag information all exists in a relational database, the goal of the method is to produce a query containing a "self-JOIN" that finds all items having a tag and then figures out what further tags could be used to narrow the search. A sample query when looking one level "deep" (ie. having searched for items with tag "foo") might be something like this:
SELECT t2.tag_id AS id, tags.name, tags.taggings_count
FROM tags, taggings AS t1
JOIN taggings AS t2
WHERE t1.tag_id = 38
AND t2.taggable_id = t1.taggable_id
AND t2.taggable_type = t1.taggable_type
AND tags.id = t2.tag_id
AND t2.tag_id NOT IN (38)
GROUP BY t2.tag_id;
And at two levels deep (ie. having searched for items tagged with "foo" and "bar") might look like:
SELECT t3.tag_id AS id, tags.name, tags.taggings_count
FROM tags, taggings AS t1
JOIN taggings AS t2
JOIN taggings AS t3
WHERE t1.tag_id = 38
AND t2.tag_id = 40
AND t2.taggable_id = t1.taggable_id
AND t2.taggable_type = t1.taggable_type
AND t3.taggable_id = t1.taggable_id
AND t3.taggable_type = t1.taggable_type
AND tags.id = t3.tag_id
AND t3.tag_id NOT IN (38, 40)
GROUP BY t3.tag_id;
Clearly this kind of self-JOIN can't or shouldn't go on forever, but it works quite adequately when any point within the object graph is reachable via a small number of tag "hops". In that particular implementation, I had a hard-coded limit of no more than five JOIN clauses, which was enough for my data-set, but I think it would have kept on working comfortably up to around ten, and perhaps more, easily enough.
So, an option we have for rapidly prototyping an initial version of Filechute is to simply shove all the tag information in a SQLite database and use a self-JOIN trick like this one as a proof of concept. Later on, we can consider creating a bespoke data structure optimized for this specific use case.
The "tag cloud" metaphor was very "Web 2.0" and somewhat in vogue at the time I wrote that Rails app, but for Filechute I think an iTunes-inspired interface is probably going to look better and be more ergonomic. Its much-loved "Column browser" lives on even today in Apple Music, if you dig around in the menus and enable it:
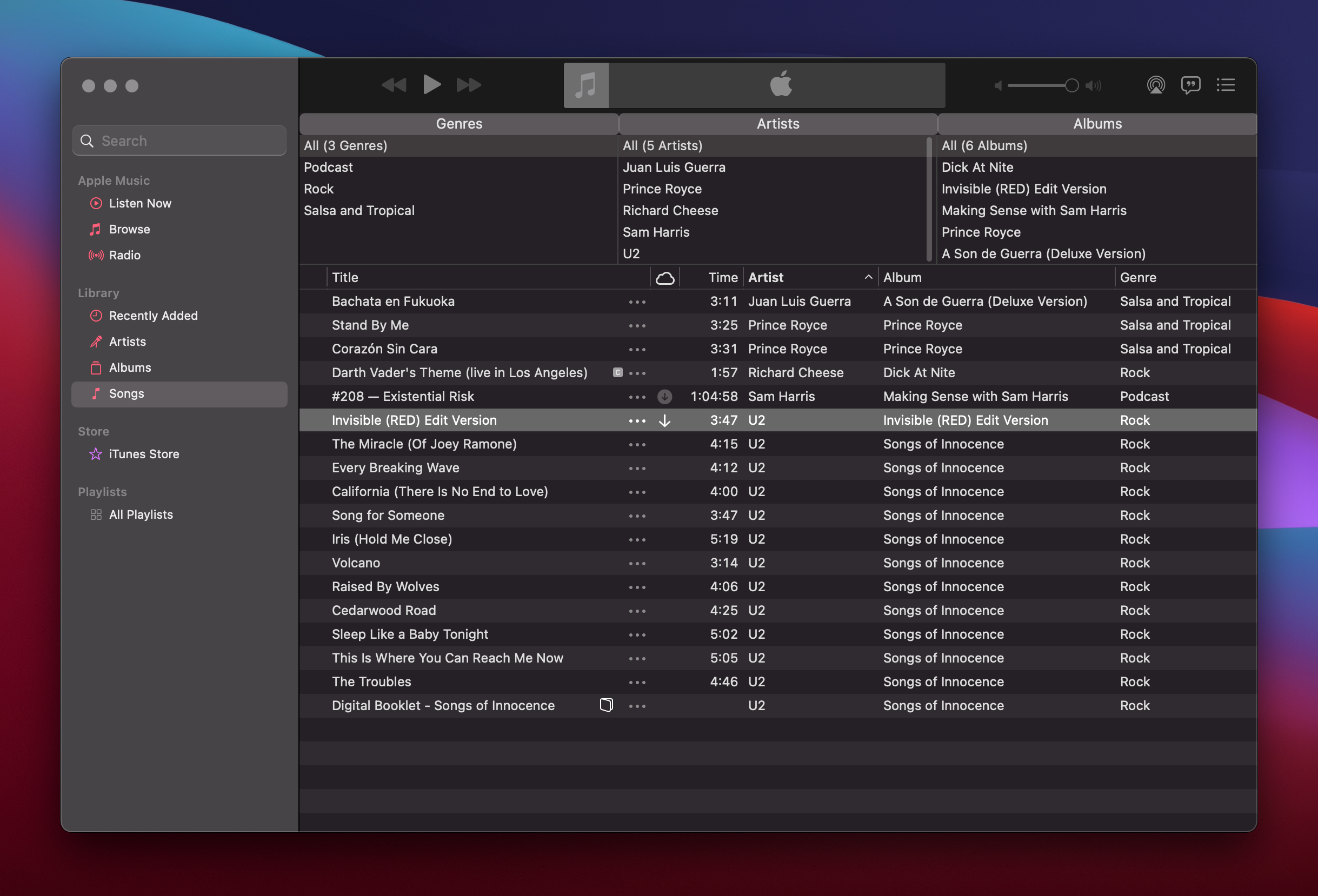
Without dwelling too much on the pathetic total of four songs in my library6 (not counting the utterly cringe-inducing presence of the "Songs of Innocence" album from U2 that continues to parasitically infest my device years after 2014, when it was put there by Apple in one of the most misguided marketing campaigns in recorded history) we can see columns up top that permit one to select genre, artist, and albums — any selection in these columns refines the search, showing only the matching entries (and possible refinements) in the other column; the main listing below the columns reflects the filtered result. And of course, the ubiquitous side-drawer on the left provides a home for shortcuts to other places and favorites.
Overall, this UI is a frickin' delight to use, as intuitive as it is powerful. At the top of each column we find obviously labeled entries for "All (3 Genres)", "All (5 Artists)", and "All (6 Albums)" that provide us with a quick escape hatch to broaden our search, should we ever scope it too narrowly by accident. And consistent with the established patterns in the OS, we can navigate this thing easily with the keyboard using standard, easily-guessable shortcuts for moving between columns, going up and down, selecting items, extending an existing selection, or removing it. The pointing device, likewise, can be easily used to do the same, and we can make use of the familiar keyboard modifiers — Shift, and Command — to make and adjust both contiguous and non-contiguous selections. In another familiar macOS UX mechanism, as seen in the Finder and elsewhere, typing initial letters while one of these columns has focus allows one to jump ahead to a matching row. This is quite simply one of the most well-thought out, pleasant, and effective pieces of human-computer interaction I've ever seen7.
So, how would we apply this UI pattern to navigating a tag based file system? My proposal is that we take the "tag cloud" idea from Web 2.0, along with the refinement mechanism from my old Rails app, to allow you to "drill down" through the tag space, narrowing your search, by moving through the columns. In the leftmost column we have all of the tags. In lieu of using font size to indicate importance, we could add a small counter showing counts8 next to each tag. I would think that showing the tags by alphabetical order would be a reasonable default sort order, but we could also offer to sort things by recency, by tag count, or perhaps let users pin favorites to the top. As in iTunes, multiple selection would give us "OR" semantics.
As we click in a column, that would refine what we would see in the column to the right. For example, if you click "foo" in the left column, and we have items tagged with "foo" and "bar", plus "foo" and "baz" in the store, the right column would filter down to show "bar" and "baz". Clicking in the right column would then apply "AND" semantics; if I click on "bar" then I'll see items tagged with both "foo" and "bar", and the next column over will offer me further options to narrow the scope of my search, should I wish to do so.
"Seeing items" means seeing them in the main list view underneath the column browser. What does an item look like, given that it in essence, it is identified by its content hash? We can certainly show the hash in this list, but it is not the most useful information. On the left edge, I would expect to see a "name" but you could also think of it as a "description". Names are arbitrary text and need not be unique. In the same way that a family might contain two people called "John", our list can contain multiple distinct items with the same name. Names can be derived from the filename (and perhaps via some other "smart" forms of inference based on content or other contextual clues) when an item is added to the store, and overridden by the user at any time. Additional columns may display other metadata and tag information for the items: creation/addition date, tags, or anything else that we consider to be of interest. The list should be sortable by any of these fields.
This is not an exhaustive definition of all the possible flows, but I think it gives a basic idea of the overall feel and color of the desired interaction. And somewhere in the UI, just like we see in iTunes, we'd need a ubiquitous text field, so that you can search using free-form text and see the view update in response as you type; this is to say, if you want to see an item tagged with "foo", "bar", and "baz" (or if we're being more realistic, "tax", "2018", "w-2") you're not forced to go through the column interface to get there — you should be able to just type "foo bar baz" (or "tax 2018 w-2") and get to the same place. In the initial version, the text field might be used just to search by tag names; later iterations could also search other forms of metadata, or perform full-text search of the file contents themselves. It is possible that we might want additional secondary text fields for filtering the various columns and lists in the UI.
So, at this point, we have a notion for how we might add objects to a store, how we might tag them, and a UI for finding items based on those tags. The funny thing is that Apple has already provided us with a means to tag items in the filesystem, as well as tools for searching it (eg. Spotlight), but I am not sure that anybody is really using tags. The reason, I think, is that they feel tacked on as an incremental afterthought bolted on to a hierarchical filesystem; they don't really feel like first class citizens and they UX certainly doesn't feel like it has been designed around tags as central organizing concept. I think that even the rough sketch shared above goes some way to showing how powerful and useful a truly tag-centric system might be if designed that way from the ground up.
Let's go into a little bit more detail about the exact semantics of what it means to organize information in this way. Based on what we've talked about so far, we can make the following statements:
- Files are addressed by their content and not by their names.
- We locate files of interest by using tags attached to those files.
- A file may have any number of tags.
- Tags may be applied to any number of files.
- We can search for files using an "AND" relationship (ie. "drilling down" rightwards through the column browser).
- We can search for files using an "OR" relationship (ie. by using multiple selection in the columns browser).
- Our text-based search could assume "AND" semantics initially, but easily be extended to support explicit syntax for making combinations of "AND" and "OR", additionally using parentheses to establish precedence.
- Although files are addressed by content, there is nothing stopping us from recording additional metadata about them, including their original name, file extension, embedded metadata, or a user-provided description, to assist in locating them.
- File names, if recorded as metadata, need not be unique, because they are never used to address (identify) specific files.
Where do we store file metadata?
As mentioned previously, we can store tag information in a SQLite database or a bespoke data structure, but this is only one specific instance of metadata that we might wish to associate with a given file. Here again, we can leverage a generic database or a custom data structure of our own design, but in the abstract, we can think of it as a key-value store9. Some examples of things we might want to record include:
- Original filename of the item when added.
- File type information, as encoded by the file extension or otherwise discernible from the file contents.
- Timestamp information about when the item was added.
What happens when you add the same file twice?
Given the preceding design, any file added a second time with the same contents will have the same content hash, which means that we don't have to write the corresponding object to the store (it is already there), nor overwrite it, because it is effectively immutable (if it were to change, it would have a different content hash, so would occupy a different place in the store). But because we record metadata as well, we have the option of creating a "paper trail" for this kind of redundant action in the data store. It's not clear whether such information would be practically useful, but the cost of recording it would be low enough to warrant doing it "just in case": for example, we could trivially record the timestamps and total count of times when a particular item was added, or note when the same content was added with different file names.
What happens when two files hash to the same value?
This is really just a way of restating the previous scenario (ie. of adding the same file twice). The only reason two files should hash to the same value is if they really are the same file; given a worthy (cryptographically strong) hash function, we can disregard the possibility of unintended hash collisions. Of course, I can add two zero-byte files to the store, calling them "letter.pdf" and "avatar.png", and they will hash to the same value just like any other identical pair of sequences of bytes would, but despite their distinct names their identical contents belies the truth — they are the same thing. We can record the fact that these two things were added in our metadata registry, but we'll only write one copy of the underlying object to the store.
How do we remove items from the store?
We have a couple of options here. We could, of course, just delete the objects from the store, but that sounds awfully destructive. Instead, we can update our metadata to indicate that the object is "soft-deleted", or we can remove the metadata but leave the underlying object on disk. Either way, we need a GC mechanism that can come along later to clean up the straggling object data, and the tombstone record in the metadata, if we have one. Of these, modeling this all explicitly with tombstones seems like the right way to go, because it is conservative by nature and reversible in practice.
How do I open items in the store?
We've talked about finding items in the store, but that's not the same as actually opening them. Say I have a PDF that I want to print out, and it happens to live at a mysterious location like $STORE/objects/59/6b3f7666412e07baba14f4620d85d221631a7b, I need some way of getting that data into a program like Apple's Preview app. It's true that a mature version of a Filechute app is probably going to have to offer some kind of built-in preview functionality, but even if that functionality becomes very sophisticated and comprehensive, we'll always need the basic ability to expose the actual file objects to other applications in a useful way.
Now, the items in the store must remain immutable, so we can't let applications have access to the actual inode-backed data of a file (if they had such access, they could mutate the file, which would mean that the contents would no longer hash to the same value, the streams would cross, and bad things would happen). Instead, we must provide access to copies of the file data, which conveniently provides us with an excuse to write out that data into a neat little file in a temporary location with a proper file extension which will help an app like Preview to know how to show the darn thing. We can provide a reasonable default experience with double-click (or Command-O), and offer an "Open with..." menu for those times when we want this copy to be sent someplace different.
How do I edit items in the store?
This operation is related to both deletion (because any edit that changes file contents will produce a new hash, the object containing the old contents will need to be cleaned up) and to opening (because you can't actually mutate objects in the store without opening a copy of them and operating on that). Editing a file, then, effectively means opening it, modifying it, saving the updated result back to disk, and then notifying Filechute that it should take the contents from the file and use them to update the store. I don't know if there is any nice way of detecting this automatically, although we can certainly try to watch the filesystem for modifications to the temporary file, but we always have the fallback of providing a big fat "Update" button in Filechute that the user can click on whenever they're done and want to commit the changes they've made to the file to the store. At that point, we can engage the already mentioned deletion machinery to clean up the old object (once again, either nuking it immediately, which is a bit dangerous, or using tombstoning and metadata updates to leave a paper trail that we can later deal with with a definitive GC operation).
How to structure the index
Although we've taken some inspiration from relational databases in designing this system, and we may even make use of such a database in a prototype, it's important to note that we don't actually need the full flexibility and generality of a relational database engine. Ahead of time, we already know the schema and the shape of all possible queries. So while we might end up building a database-like index that uses B+ trees, we don't need to build a query parser, optimizer, or any of the supporting machinery that a real database would need in order to support arbitrary queries. Nevertheless, describing the data model in terms of tables and indices provides us with a handy shorthand, so let's start there:
CREATE TABLE `tags` (
`id` INT unsigned NOT NULL AUTO_INCREMENT,
`name` VARCHAR(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci,
UNIQUE KEY `idx_name` (`name`) USING BTREE,
PRIMARY KEY (`id`)
);
CREATE TABLE `objects` (
`id` INT unsigned NOT NULL AUTO_INCREMENT,
`hash` VARCHAR(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci,
UNIQUE KEY `idx_hash` (`hash`) USING BTREE,
PRIMARY KEY (`id`)
);
CREATE TABLE `taggings` (
`id` INT unsigned NOT NULL AUTO_INCREMENT,
`object_id` INT unsigned,
`tag_id` INT unsigned,
KEY `idx_object_id` (`object_id`) USING BTREE,
KEY `idx_tag_id` (`tag_id`) USING BTREE,
PRIMARY KEY (`id`,`object_id`,`tag_id`)
);
CREATE TABLE `metadata` (
`id` INT unsigned NOT NULL AUTO_INCREMENT,
`object_id` INT unsigned,
`key` VARCHAR(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci,
`value` VARCHAR(256) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci,
KEY `idx_object_id` (`object_id`) USING BTREE,
KEY `idx_key` (`key`) USING BTREE,
KEY `idx_value` (`value`) USING BTREE,
PRIMARY KEY (`id`,`object_id`,`key`)
);
So, to find all the items with the "foo" tag, we'd use a query something like:
SELECT objects.hash
FROM objects
JOIN taggings
ON taggings.object_id = objects.id
JOIN tags
ON taggings.tag_id = tags.id
WHERE tags.name = "foo";
There are some interesting possibilities if we wanted to express this model in a non-relational way. For example, instead of having a taggings table, objects might indicate what tags apply to them in the form of a bitfield (where a 1 bit indicates the tag is present, 0 indicates that it is not). In a practical system managing tens of thousands of files, there might not even be a thousand tags, which means that a 1000-bit bitfield could suffice. This represents a trade-off: without the taggings table we can avoid some potentially expensive joins and replace them with cheap bitwise operations (eg. bitwise AND) for some operations, but we also lose a place where we could potentially add richer metadata (like recording when a tagging was created, or having the ability to soft-delete taggings by adding tombstones to them).
If we step outside of the relational model, instead of having objects, tags, and taggings tables, we would have a single index data structure that would probably take the form of a B+ tree mapping from tags to object hashes (ie. analogous to the taggings table). A B+ tree is interesting here because it would provide us with an efficient way to do range queries, as well as provide predictable runtime for all operations (by virtue of being a balanced tree), although in a small enough data-set, the actual choice of data structure hardly matters (other than wishing to eschew unnecessary complexity).
Operations we need to support:
- List all items in name order.
- Sort all items arbitrarily by any other metadata property.
- Given a tag, list items with that tag.
- Given multiple tags, list items with all of those tags.
- Sort these items arbitrarily by any other metadata property.
- Given an item, report which tags apply to it.
We could have a tag index for looking up by tag:
| key (tag, object) |
| --------------------------- |
| ("foo", "aa/0000000000...") |
| ("foo", "ff/9999999999...") |
| ("bar", "aa/0000000000...") |
And a name index (plus additional indices for any other metadata that we might want to sort by or look-up by):
| key (name, object) |
| ------------------------------------------ |
| ("Annual report 2021", "aa/0000000000...") |
| ("ID card.pdf", "ff/9999999999...") |
For quickly answering the question, "Which tags apply to this object?", we need another index, where we would probably want one entry per tagging, for simplicity, as opposed to storing multiple tags in a single list-like record.
| key (object, tag) |
| --------------------------- |
| ("aa/0000000000...", "bar") |
| ("aa/0000000000...", "foo") |
or alternatively, we could piggy-back on tags-as-special-case-of-metadata to do something like this (ie. tags as metadata properties without values):
| key (object, metadata property, metadata value) |
| ------------------------------------------------ |
| ("aa/0000000000...", "createdAt", 1638726047760) |
| ("aa/0000000000...", "foo", null) |
| ("aa/0000000000...", "bar", null) |
Searching for multiple tags involves multiple passes over the tag index. In one approach, we can either grab all the matches into a temporary "view" (ie. another B+ tree) in memory and then filter them, or we can do a cruder set of linear scans to prune away non-matching items. In another approach, we can query the main index multiple times and then combine the results. Yet another way to do this is by filtering on whichever tag which will reduce the cardinality of the result set most aggressively, and then do a pass that collects all of the tags applying to each item into an array or set (probably an array, given that the number of tags expected to apply to each item doesn't warrant the overhead of constructing the set), and then query that. In short, we have options.
B+ trees are interesting here because we can organize them into blocks, which will be useful for the next phase, where we want to be able to synchronize these indexes through Le Cloud. Breaking the index up into chunks as opposed to a large monolithic blob may make this synchronization more efficient, because it allows us to do partial synchronization, or synchronization in parallel.
Phase 2: Adding synchronization
At some point, it might be interesting to build in synchronization functionality, such that Filechute wouldn't depend on another application like Sync or Dropbox to replicate copies to other places. Why do this? Well, it provides us with more control: we can potentially implement a more direct solution with less overhead that may wind up being more efficient.
The basic idea here is to encrypt file blobs before dumping them in an S3 bucket (or similar). In the simplest possible implementation, we wouldn't be obfuscating the hashes at all, which means that if someone were able to list your bucket and happened to have a copy of the same files as you, they could deduce that fact from the presence of hash collisions. I'm not thinking about using this to store anything more sensitive than my tax returns though, so this could be ok. Having said that, we could quite easily obfuscate the hashes by adding a layer of indirection, if we wanted to, by hashing the object ID plus a salt that we store along with the encryption key. Encryption would be handled as follows.
Most likely would use something like AES encryption in CBC mode10, probably after studying this Stack Overflow answer warning you not to implement your own crypto and doing it anyway. I'm not sure if there is some clever way for having per-device, revocable keys without having to re-encrypt the data, but without having researched that possibility, I'd say we could go for this simple scheme: the data is encrypted with an encryption key that is itself encrypted with multiple per-device keys. Any time you add a device, you add that device's key so that it, too, can decrypt the encryption key. In the event that you need to revoke a key, you have no way of removing the data from a compromised device, but you can remove that device's key from the set of keys with access to the encryption key, by re-encrypting the data with a new key, and giving only the non-revoked keys the opportunity to decrypt the encryption key. The nice thing is that these devices won't have to download everything all over again because if they already have the plaintext for a given content hash, there is no need; they only have to download new blobs and decrypt those using the new key. As a general source of inspiration though, the Arq encryption scheme is a good example of a cloud based data storage scheme that a lot of people trust.
Appendix: Bits and pieces
I'm going to stop here because this is probably enough for one post, but there is plenty more that could be discussed. When I started writing it, I had intended it to be a briefer summary of technical decisions, and in the end it has turned out to be more of a series of questions and options, than of concrete answers. Oops.
One topic that we haven't touched on is data integrity and an fsck type process that could be used to check the integrity of objects in the store. As you stash more and more gigabytes of stuff into the store, and start moving it back and forth across network boundaries, the odds that it might get corrupted somewhere along the way only increase.
On the subject of indexing and data formats, I've thrown the term "B+ tree" round a few times without actually describing how the bytes would be serialized to disk. It's pretty easy to describe how such a tree would be laid out in memory, where pointers can easily create relationships between nodes, but in an actual implementation you also need to spell out how you are going to persist that stuff to disk and read it back in when your app is starting up.
Another subject is implementation languages for a prototype. I immediately thought of TypeScript because it is so darn familiar and easy to sketch out proofs of concept, but Rust seems better suited for the real deal, which is very much going to be dealing with bits and bytes. But then again, maybe this should be my excuse to learn Swift, seeing as I'm going to want a slick native macOS UI for this thing, and it's been just long enough that I've recovered from the trauma of having used Xcode to make a living in the 2000s.
Nevertheless, I'm going to leave a proper exploration of those matters for another day and another post. Maybe next time I'll be able to tackle my original goal of providing a somewhat concise technical summary of how all this is going to look like.
2026 update
Now that coding agents have gotten as good as they have lately11, this project has gone from "something I'd like to implement one day when I have time" to "something I can create a proof-of-concept for in a weekend".
After working in the capricious Apple ecosystem for years, I was wary of making a new investment in an Apple-dependent language and toolchain, but the cost of producing this kind of POC is now so low that I feel totally fine calling it "throwaway code" and moving forward with it. The work-in-progress is up on GitHub at wincent/filechute.
-
I'm inclined to use Skein because the implementation is relatively simple and I've used it happily elsewhere, but in reality I'd be fine with using any reasonable hash function that has a well-vetted implementation written by actual, practical cryptography experts in the programming environment that I'm working in. ↩
-
Apple's quaint(?) decision to encourage the usage of a space-containing path ("Application Support") for use by applications is probably a blessing in disguise; the presence of the space has probably caused countless latent bugs to manifest themselves over the years, but it's good to have a forcing function that obliges you to flush out the possibly invalid assumptions you're making about the context in which your code is going to run. ↩
-
If we ever need to deal with greater scales, we have the option of further fanning out the object storage by adding an extra intermediate layer of partitioning (eg.
a7/90/65aca746c25342a83183d5e9a56262d1d826), or borrowing the "packfile" concept from Git, wherein "loose objects" get stored together in aggregate bundles (and additionally leverage a technique called delta compression which stores only the differences between objects instead of the full contents of objects themselves). In the spirit of YAGNI, the initial proposal here doesn't include a suggestion to do anything beyond simple storage as loose objects. ↩ -
The only "metadata" that Git tracks about files beyond their contents, other than their names, is whether they have their executable bit set. It's also capable of capturing whether a file is a symbolic link (and if so, where it points to) as opposed to a regular file. ↩
-
Thirteen years ago, apparently... The link in the commit message now 404s, but the issue it's citing can still be seen at wincent.dev/issues/1209, and it provides some additional interesting context. ↩
-
I'm a Spotify user. ↩
-
My only disclaimer here would be that I am not a real Apple Music user, and I'm mostly speaking about the golden days early on in iTunes' history. I'm reasonably sure that if I had to use this application in anger, I'd find a lot of little annoying ways in which Apple has added friction and unwanted "encouragement" to return to the Store view, among others things. ↩
-
Other options include color-based indication, or a small bar whose width would represent the count. ↩
-
It may be tempting to treat both key-value metadata and tags as two instances of the same thing (specifically, tags being a special case key-value pair where the value is null), but I suspect this is probably a mistake. Giving primacy to tags obliges us to put them front and center in the design, and while I can't predict where this emphasis will lead, I think it's important to explore it — we can always change our minds later. ↩
-
See also the Wikipedia article on block cipher modes. ↩
-
So good, in fact, that I am able to supervise the agent writing Swift, a language I've never written and barely read, and it produces a working result in pretty short order. ↩